
In recent articles, we have read about the fast pace of developments in AI-based weather modelling. Considering these developments, it is imperative to keep in mind that fast does not necessarily mean good. For example, while many AI weather models demonstrate to be competitive to NWP for some variables and especially in the longer term, they also struggle with expressing extreme weather situations. For example, think wind speeds related to tropical storm systems or predicting extreme precipitation events reliably.
Now, what is ‘good performance’? And performance compared to what? How can we compare the performance of an AI weather model with another AI weather model? And how to compare them with NWP models? These are valid questions to ask when assessing the performance of AI weather models, if not any weather model, something we do frequently at Infoplaza. Typically, such verifications are performed to identify where models perform well and where they show weaknesses. It is key for knowing when to use which model in what situation.
The WeatherBench benchmarking framework was created to unify and standardize these verifications: to create a benchmark tool, if you will. It is already used in many discussions and verifications, including in some recent works on new AI weather models. Slowly but surely, it’s becoming the de facto standard for model comparison in the era of AI weather models.
In this article, we’ll take a closer look at the why, what, and how. We start by looking at a use case that can only be derived through verification: that of Pangu-Weather’s difficulties with predicting extreme wind speeds. This is followed by the history of WeatherBench – and by looking at WeatherBench scores, to see what scores are available.
A clear need for standardized verifications
Let’s first understand the reason why it is important to verify weather models – irrespective of their approach, that is, whether it is an AI-based weather model or an NWP model. As Box (1976) already stated, “all models are wrong, but some are useful”. To determine which models are useful, it is important to understand in what cases they are typically wrong – as from there, it automatically follows when they are useful.
The verification of the Pangu-Weather model proves to be a good example for showing the added value of verifications (Bi et al., 2022). Recall that Pangu-Weather is a set of Vision Transformer based AI weather models which are trained using 39 years of ERA5 reanalysis data. The model first cuts the input variables into pieces (i.e., patches) before producing patches of the next time step, which are then merged, producing the actual forecast.
The 39 years comprising the training dataset span 1979 to 2017. This is a sufficiently large time span to capture most of the weather patterns that can be statistically present in any region of the world. Subsequently, during training, data from 2019 was used for validation purposes (i.e., to steer the training process while training). Finally, post-training, the years 2018, 2020 and 2021 were used for testing i.e. for verification (Bi et al., 2022). Likely, the years 2018 and 2019 were swapped between training and validation to ensure that temporal correlations aren’t present between the training and validation datasets.
From the verification, these non-exhaustive insights were discussed in the paper:
• Globally in space and time, when looking at Root Mean Square Error (i.e. average error), Pangu-Weather shows competitive performance compared to ECMWF’s IFS.
• This is true for upper-air weather variables and surface weather variables.
• When considering extreme weather events (such as storms), Pangu-Weather proved to be competitive when predicting the position of such events. Analyzing the performance for their magnitude (for example, 10-meter wind speed when considering extreme weather events) showed that Pangu-Weather performed worse compared to IFS at longer lead times.
Using model verifications thus leads to better understanding of scenarios in which the model performs better and when it doesn’t. That way, meteorologists can develop an intuition for the reliability of a model in any weather situation. Thus, verification studies ultimately benefit the quality of our weather forecasts – effectively, of any weather forecast.
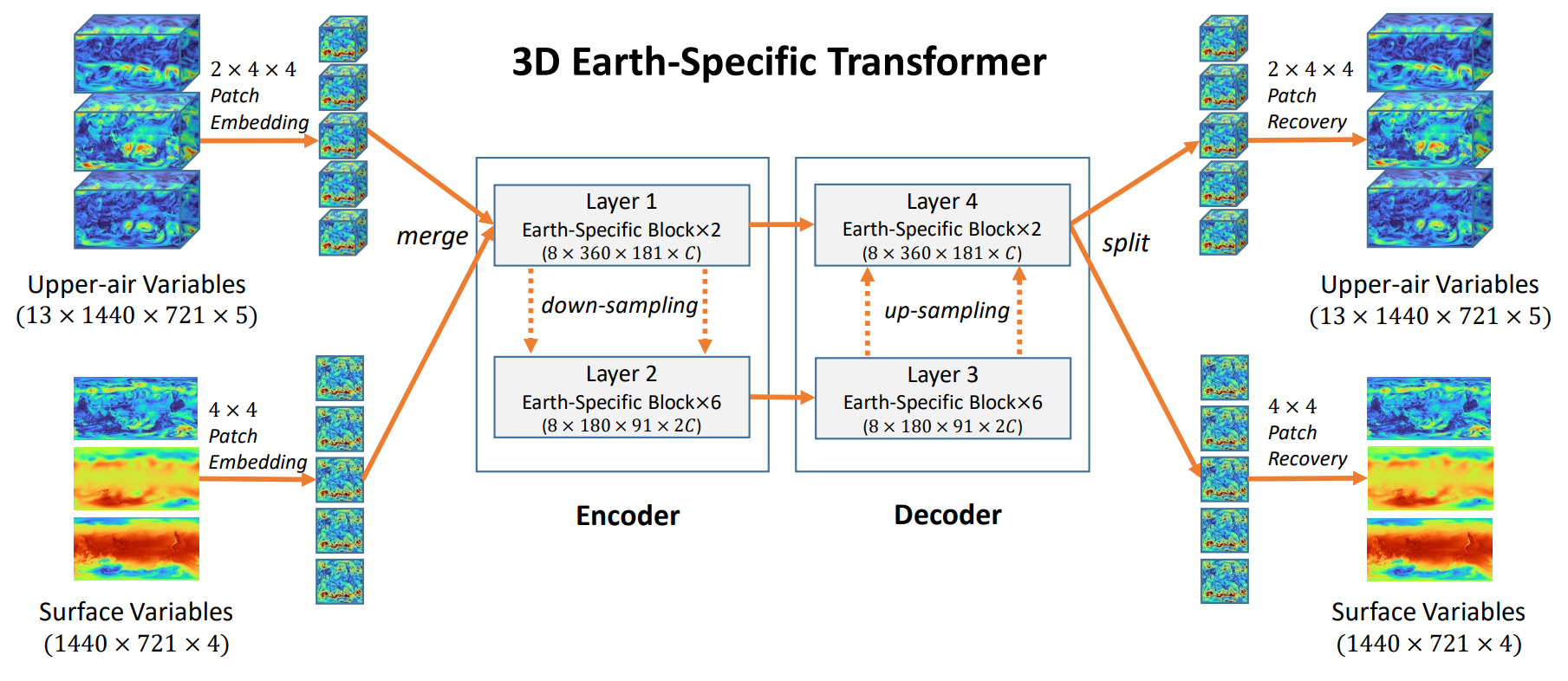
The internals of the Pangu-Weather model (Bi et al., 2022). Upper-air variables and surface variables are images, which are then cut into patches; see the left part of the image). Using an encoder-decoder architecture with Transformer layers, the model learns to produce the next state of the atmosphere as pieces, which are then recombined into images.
How the WeatherBench framework was created
The need for a common evaluation dataset, for clear evaluation procedures and for evaluation benchmarks was also recognized by Rasp et al. (2020). They proposed the WeatherBench dataset to be used “for data-driven weather forecasting”. According to the authors, in 2020, “[the meteorological sciences lacked] a common benchmark challenge to accelerate progress [in AI-based weather modelling]”.
In their work, they proposed a preprocessed training and validation dataset based on ERA5 reanalysis data. Given the sheer size of this dataset (with 700 GB for a single vertical level), they chose to regrid the data to coarser resolution: to between 1.405 degrees and 5.625 degrees. The latter resolution is primarily used for evaluation purposes. Data is made available for 13 vertical levels and various surface-level variables, such as 2-meter temperature and wind speed at 10 meters.
Similarly, the authors proposed precisely defined evaluation criteria to ensure a unified approach for evaluating models. To ensure that evaluation is done in the same way, it is suggested to use 2017 and 2018 for evaluation, approximately from 4 January 2017 onwards to avoid overlap between training and evaluation data weather wise. The focus for evaluations is the medium-term range between 3 and 5 days ahead.
Evaluation-wise, the primary loss function (which suggests how poorly the model is performing) is the mean latitude-weighted Root Mean Square Error (RMSE) over all forecasts. What this means is that for each grid cell in the forecast, RMSE is calculated (by taking the square of the difference between prediction and true value and then taking the root square of its mean) and subsequently weighted by latitude. This ensures that areas around the Equator are as important as areas around the poles, which is not the case with unweighted RMSE because the Earth is a sphere.
Similarly, there are various baselines to compare AI based weather models against:
• Firstly, and typically, a persistence baseline, which effectively means that the data with which to generate a forecast is used as is as if it were the forecast (“today’s weather is tomorrow’s weather”, as written by Rasp et al.). This is typically a solid baseline as longer-term weather is present in both time steps, but generally also quite a beatable one because there are a lot of differences (as today’s weather is never truly tomorrow’s weather).
• Then, they introduce a climatology baseline, which effectively considers the average weather at each grid point as the forecast. Since seasonality plays a large role in general weather at one point in time, it is also a solid and typically beatable baseline.
• Operational weather models, in this case the ECMWF IFS model, regridded to the same evaluation resolution. However, because these models may have a slight advantage as they were regridded from a high-res grid, another baseline is proposed – that of NWP models run at coarser resolutions (in this case the 5.625-degree resolution proposed for evaluation).
• Finally, machine learning based baselines. One beatable model is a linear regression model which attempts to predict the next timestep without considering spatial positions; another is a simple convolutional neural network (i.e. an approach similar to that of the really early days).
In other words, the first version of WeatherBench as proposed by Rasp et al. (2020) provided the first unified dataset, unified and precisely defined evaluation criteria and a set of baselines using which AI-based weather models can be compared.
| What | How |
| Used data | ERA5 reanalysis data with resolution between 1.40 and 5.625 degrees. |
| Used levels | 13 vertical levels (between 50 and 1000 hPa), various surface-level variables and various time-invariant fields, such as land-sea mask and soil type. |
| Evaluation focus | 1 to 14 days, but primarily 3 to 5 days ahead |
| Evaluation years | 2017 and 2018, accounted for overlap between training data and evaluation data (thus starts on 4 January). |
| Evaluation resolution | 5.625 degrees |
| Primary verification fields | 500 hPa geopotential and 850 hPa temperature, as they both provide information about weather at larger scale. |
| Primary loss function | Mean latitude-weighted Root Mean Square Error (RMSE) over all forecasts |
| Used baselines to compare models against | Persistence and climatology, operational NWP models, NWP model run at coarser resolution, linear regression and simple CNN-based AI weather model. |
Characteristics of the first version of the WeatherBench benchmark dataset, from Rasp et al. (2020).
Since 2020, a lot has happened in the field of AI-based weather forecasting. In 2022, a first generation of AI-based weather models appeared that provided forecasts at 0.25 degrees, quickly followed by a second one in 2023. Unsurprisingly, these successive developments revealed shortcomings in previous works. Garg et al. (2022) demonstrated one in Rasp et al.’s work: it exclusively focuses on deterministic prediction, while probabilistic approaches (such as ensemble models) have added value in the medium- to longer-term range.
Extending WeatherBench to probabilistic forecasts
In their work, they thus extended WeatherBench by adding a probabilistic dimension to the original WeatherBench verification criteria and baselines (Garg et al., 2022). Specifically, they:
• Used Monte-Carlo Dropout to produce a stochastic prediction i.e. a prediction that is slightly but randomly different every time. Do this 50 times, and you get a 50-member ensemble AI forecast which hopefully captures the range of possibilities in e.g. temperature.
• Predict the distribution parameters instead of the direct output. Deterministic AI weather models use the input to predict the next atmospheric state. If you predict the distribution parameters instead, you can draw new samples from that distribution – and effectively generate a many-member ensemble AI forecast.
• Implementing categorical predictions into models, where the outputs are first distributed into bins (such as “temperatures between 5-10 degrees”, “10-15 degrees”, and so forth) while the model predicts probabilities for each bin.
What’s more, Garg et al. proposed using another evaluation loss function for probabilistic forecasts: the Continuous Ranked Probability Score or CRPS. It helps by not only looking at the forecasted value (i.e., was it right?), but also at the range of predicted values (i.e., how many of them were right?). CRPS is already commonly used when evaluating ensemble forecasts by NWP models and is thus a good fit.
The second generation of WeatherBench
WeatherBench 2 is an enhanced benchmark introduced by Rasp et al. (2024) to accommodate developments in AI-based weather forecasting since the release of WeatherBench 1. Building on this original framework, among others, WeatherBench 2 provides additional data, updated metrics, and new baselines.The ERA5 reanalysis dataset remains the main dataset in WeatherBench 2. Instead of the relatively coarse resolutions from the first version, data is offered at a 0.25-degree resolution across 137 vertical levels, although evaluation happens at 1.5 degrees with a few headline scores (Rasp et al., 2024).
| What | WeatherBench version 1 | WeatherBench version 2 |
| Provided data | ERA5 reanalysis data with resolution between 1.40 and 5.625 degrees. | ERA5 reanalysis data with up to 0.25-degree resolution. |
| Provided levels | 13 vertical levels (between 50 and 1000 hPa), various surface-level variables and various time-invariant fields, such as land-sea mask and soil type. | 137 vertical levels and various surface-level variables, as well as time-invariant fields like geopotential, land-sea mask and so forth. |
| Evaluation focus | 1 to 14 days, but primarily 3 to 5 days ahead | 1 to 14 days ahead |
| Evaluation years | 2017 and 2018, accounted for overlap between training data and evaluation data (thus starts on 4 January). | Primarily using 2020, with 00 and 12 UTC initialization times. |
| Evaluation resolution | 5.625 degrees | 1.5 degrees |
| Primary verification fields | 500 hPa geopotential and 850 hPa temperature, as they both provide information about weather at larger scale. | Extending version 1 with 700 hPa specific humidity and 850 hPa wind vector/speed as well as surface-level variables (the “headline scores”, Rasp et al., 2024). |
| Primary loss function | Mean latitude-weighted Root Mean Square Error (RMSE) over all forecasts | Various extra metrics, such as Continuous Ranked Probability Score (CRPS), Spread-Skill Ratio, and Stable Equitable Error in Probability Space (SEEPS) and energy spectra. |
| Used baselines to compare models against | Persistence and climatology, operational NWP models, NWP model run at coarser resolution, linear regression and simple CNN-based AI weather model. | Additional extra baselines such as ERA5-based forecasts. |
WeatherBench scores in a glance
Now that we understand the need for a benchmarking framework like WeatherBench and how it has evolved over time, let’s look at some of the outputs that can be downloaded at the WeatherBench website.Deterministic scores
One of the WeatherBench pages shows deterministic scores, which display the average performance of many forecasts of a model versus the actual weather at that time (WeatherBench, 2024a). Typically, the actual weather is represented by ERA5 data. Many AI weather models were evaluated this way and are presented on this page, allowing for easy comparison.
For example, the following image presents RMSE scores for three AI weather models (Pangu-Weather, GraphCast and FuXi) when compared against ERA5 ground truths for 2-meter temperature. FuXi (a second-generation model with improvements compared to first generation models) has superior performance to Pangu-Weather and GraphCast in the longer term, but GraphCast works a bit better at shorter lead times. What’s more, on average, both GraphCast and FuXi tend to produce better 2-meter temperature forecasts than the IFS HRES (when analyzed against its own analyses) and ERA5-Forecasts (which is IFS too, but then analyzed with ERA5 to allow for true comparison with AI-based models). Still, in the long term, none of these models beats the IFS Ensemble mean, when looking at the average error.
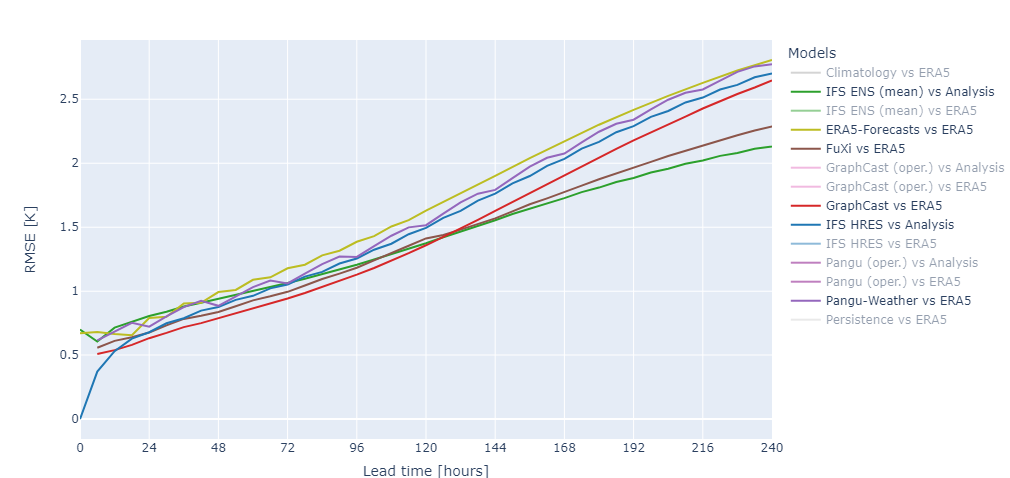
Deterministic scores for a variety of AI weather models vs ERA5, compared to ERA5-Forecasts vs ERA5 (IFS initialized with ERA5 instead of its own analysis) and NWP vs Analysis (both the IFS HRES and IFS ENS mean compared against its own analyses). Image from WeatherBench (2024a).
Probabilistic scores
We already briefly discussed the probabilistic extension to the WeatherBench framework proposed by Garg et al. (2022). These scores are also presented on the WeatherBench website, although there are fewer scores compared to deterministic AI-based weather models. The image below shows how the NeuralGCM (vs ERA5) model performs better on average compared to the ECMWF IFS mean (vs ERA5 and its own analysis), as CRPS scores are lower. This demonstrates that there is also significant potential for AI-based ensemble modelling, a topic that we will explore in more detail in a forthcoming article in this series.
CRPS score for the 500 hPa geopotential for probabilistic models. Image from WeatherBench (2024b).
Temporal scores
Deterministic model scores generally look at average performance; that is, they compute the average score over all regions and the whole evaluation period. While this provides a good average overview, weather models don’t necessarily perform equally well across the year! Using WeatherBench scores, this can be observed when looking at temporal scores – scores over time. For example, the image below – the global RMSE for 2-meter temperature analyzed over 2020 for 72 hours ahead for 3 AI weather models – suggests that models worked best between September and November, while errors were larger before and afterwards. Analyses like these can help researchers dive into reasons why models behaved that way, allowing for better weather predictions to be made.
RMSE for global 2-meter temperature as analyzed over 2020 for 72h lead time for FuXi, GraphCast and Pangu-Weather. Image from WeatherBench (2024c).
Bias maps
Similarly, when looking at the average error, regional errors present in AI-based weather models are evened out. It has been observed that models also have their strengths and weaknesses region wise, and these are omitted when looking at global scores only. Hence, WeatherBench also contains bias maps, which show bias values for many models vs ERA5 (WeatherBench, 2024d). Positive bias means that models tend to be too warm in that region while negative bias means that they are too cold.For example, in the image below, we can see the bias maps for 2-meter temperature. It is observed that Pangu-Weather tends to be too warm in many parts of the Northern Hemisphere, an effect that is exacerbated with time. This large positive bias can not be observed with GraphCast, although its own biases are exacerbated with time as well.
Using bias maps helps meteorologists develop intuition as to when to trust what model region-wise. What’s more, it allows for automated bias correction methods to be developed, which can already be as simple as adding the identified bias to the model for each region.
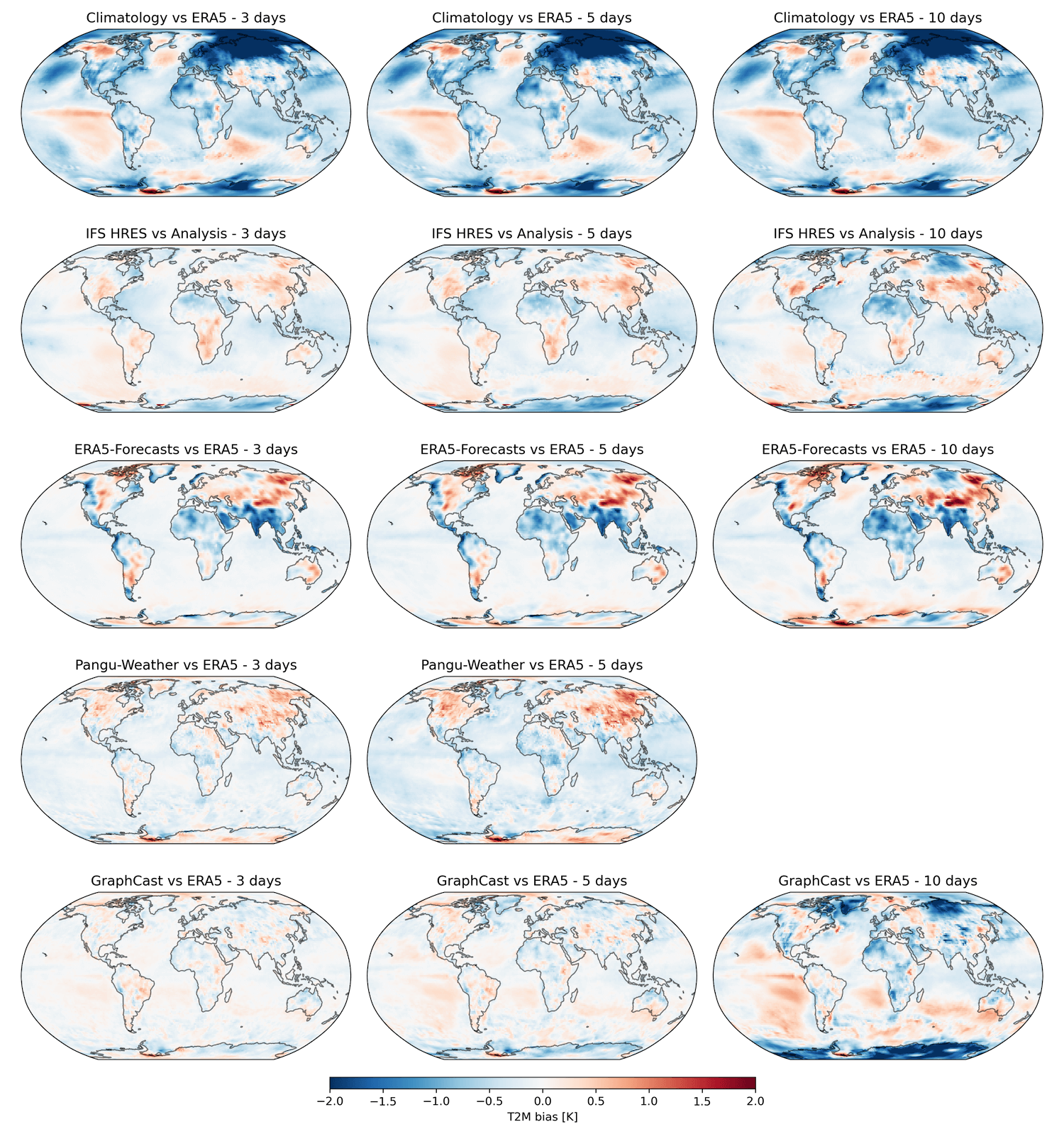
2-meter temperature bias maps from WeatherBench (2024d).
Energy spectra
One of the key shortcomings of AI-based weather forecasting is that the autoregressive character of these weather models leads to blurry forecasts. The error in the forecast for, say, T+3 hours is included when making the forecast for T+6 hours and adds up quickly. Energy spectra are a way to measure this blurriness. High power at smaller scales means that more detail is present in a forecast; less power means that a forecast is blurrier.For example, in the image below, this shortcoming can be observed. When wavelengths are larger (and thus scales are larger, too), models tend to have the same power – thus tend to be equally detailed. This makes sense because these scales describe larger-scale weather patterns. However, when looking at smaller wavelengths (and thus how expressive these models are for smaller-scale weather patterns, such as small temperature differences), differences emerge. Specifically, when it comes to detail – even though RMSE of AI-based weather models may be lower at these time horizons – ECMWF’s IFS model is still better than any AI-based weather model.
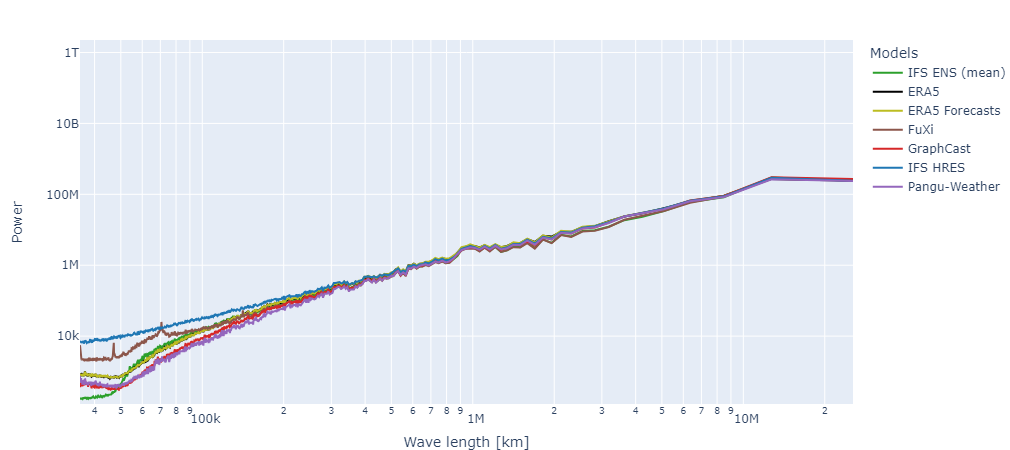
Power spectra for various deterministic AI and NWP weather models for 2-meter temperature at 192 hours ahead (8 days). Higher power means that forecasts have more detail. Lower wavelength means lower scale, thus high power at lower wavelength means that small-scale weather phenomena are captured with high detail. Image from WeatherBench (2024e).
AI vs NWP: a WeatherBench-based summary
If we summarize everything into a clear overview, we can describe the following key observations for the models present in WeatherBench:1. Deterministic AI-based weather models sometimes have lower average errors than NWP models, but we should not disregard the strength of the ECMWF ensemble mean.
2. Probabilistic AI-based weather forecasts can be competitive to this ECMWF ensemble, and there are many ways to generate them.
3. Like NWP models, AI-based models tend to show different performance in different periods of the year.
4. Similarly, AI-based models have different performance for different regions in the world.
5. The origin of much of the competitive behavior of AI-based weather models in the longer term seems to emerge from better capturing large-scale weather phenomena, as power spectra suggest that NWP models have more power i.e. more detail at smaller scales. This is especially important for forecasting extreme weather events.
If we disregard advances in AI-based weather modelling which will be discussed in forthcoming articles – such as better capturing extremes – then our conclusion so far could be that AI weather models can be useful operationally for forecasting medium- to longer-term and for general weather patterns. See here the power of standardized evaluation!
What’s next: going beyond analyses – using observations more directly
So far, this series has focused on the past – by discussing the differences between NWP and MLWP models, by introducing the first generation of AI weather models, by following up with the second generation of AI weather models and now by looking at WeatherBench. Time to look to the future now! In the next articles, we will explore recent and future developments: among others, we look at approaches which attempt assimilating observations into AI-based weather forecasts directly; we look at approaches which try solving the blurriness of forecasts, and we look at the state of AI-based ensemble weather forecasting.
Going beyond analyses - using observations more directly
Today’s AI-based weather models are reliant on NWP analyses – but new approaches are trying to work around this limitation.
Better capturing extremes with sharper forecasts
One of the downsides of AI-based weather models is increased blurring further ahead in time as well as difficulty capturing extreme weather events. Similarly, new approaches have emerged attempting to mitigate this problem.
AI-based ensemble weather modelling
Weather is inherently uncertain. The speed with which AI-based weather forecasts can be generated enables scenario forecasting with significantly more scenarios to further reduce uncertainty.
References
Bi, K., Xie, L., Zhang, H., Chen, X., Gu, X., & Tian, Q. (2022). Pangu-weather: A 3d high-resolution model for fast and accurate global weather forecast. arXiv preprint arXiv:2211.02556.
Box, G. E. (1976). Science and statistics. Journal of the American Statistical Association, 71(356), 791-799.
Garg, S., Rasp, S., & Thuerey, N. (2022). WeatherBench Probability: A benchmark dataset for probabilistic medium-range weather forecasting along with deep learning baseline models. arXiv preprint arXiv:2205.00865.
Rasp, S., Dueben, P. D., Scher, S., Weyn, J. A., Mouatadid, S., & Thuerey, N. (2020). WeatherBench: a benchmark data set for data‐driven weather forecasting. Journal of Advances in Modeling Earth Systems, 12(11), e2020MS002203.
Rasp, S., Hoyer, S., Merose, A., Langmore, I., Battaglia, P., Russel, T., ... & Sha, F. (2024). Weatherbench 2: A benchmark for the next generation of data-driven global weather models. arXiv preprint arXiv:2308.15560.
WeatherBench. (2024a). Deterministic scores – WeatherBench2. Deterministic scores – WeatherBench2. https://sites.research.google/weatherbench/deterministic-scores/
WeatherBench. (2024b). Probabilistic scores. Probabilistic scores. https://sites.research.google/weatherbench/probabalistic-scores/
WeatherBench. (2024c). Temporal scores. Temporal scores. https://sites.research.google/weatherbench/temporal-scores/
WeatherBench. (2024d). Bias maps. Bias maps.
https://sites.research.google/weatherbench/bias-maps/
WeatherBench. (2024e). Spectra. Spectra.
https://sites.research.google/weatherbench/spectra/
Interested in our upcoming articles about AI and marine weather modeling? Subscribe to our marine newsletter and don't miss a thing.


